Docomo iPhone6 + IIJ mioに乗り換えてから3ヶ月ぐらいたったのでその使用感をば。結論から言うと今すぐキャリアSIMやめてMVNOに切り替えた方がいいと思う。
料金が安い
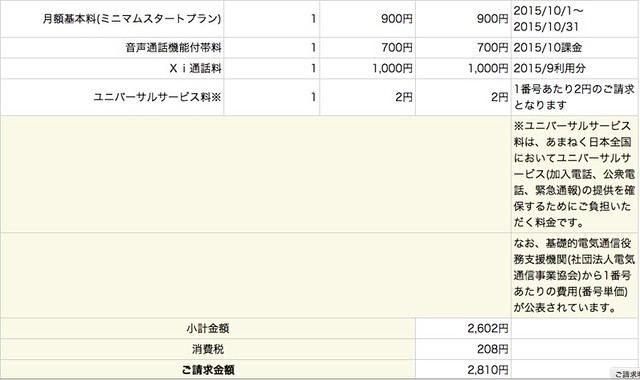
SoftbankからIIJ mioに切り替えてから、月々の利用料金が約半額になった。具体的には、Softbankの時は平均で6000円ぐらいだったのが、今では3000円以下になってる。年で考えると36000円のコストカットになるのでこれはデカい。ちなみに契約しているのはデータ通信量が3GBのミニマムスタートプランに音声通話機能をつけてる。
ちなみにこれは10月の料金明細。
200Kbpsでも意外とイケる
自分はTwitterを見ることが多いんだけど、Twitter、メール、ネットを見るぐらいであれば200kbpsでもそこまでストレスなく見れる。なので必要なとき以外はクーポンをOFFにして200Kbpsの低速回線を使うようにして、3GB/月の通信量でおさまるようにしてる。IIJ mioだとみおぽんというアプリを使うことで簡単にクーポンをON/OFFにして回線速度を切り替えられる。自分はWebエンジニアなので、あえてクーポンをOFFにして200Kbpsの回線で自分が運用しているサイトがストレスなく閲覧できるかもチェックしてる。
あと、iOS向けのGoogle Chromeを使えば、Googleのサーバーから最適化された状態でサイトを閲覧することができるので、低速回線だとSafariよりもブラウジングが快適になる。
さらに余ったデータ通信量は翌月に繰り越せるのもいい。
回線の品質がいい
MVNOなので混雑時つながりにくいことがあるかと思いきやそういうことはなく、Softbankやauなどのキャリアの回線と比べても遜色ない気がする。この3ヶ月間で「あ、なんか回線が詰まってるな」と思ったのは3,4回ぐらいだ。
端末
Apple Storeで売っているSIMフリーiPhone6(128GB)は約12万と高いので、じゃんぱらで中古のDoCoMoのiPhone6を7万円で買った。だいたいのMVNOはDoCoMoの回線を使っているので、バカ高いSIMフリー端末じゃなくてもOKっていうのは意外と知られていないっぽい。
まとめ
というわけでまだ3大キャリアSIMで消耗している人は今すぐMVNO SIMに切り替えましょう。このリンクからIIJ mioに申し込むとデータ通信量が2ヶ月間10%増量されます。

IIJ IIJmio SIM 音声通話 パック みおふぉん IM-B043
- 出版社/メーカー: IIJ
- 発売日: 2014/03/29
- メディア: エレクトロニクス
- この商品を含むブログ (5件) を見る
